research
Research map organized around the questions I am asking, not the papers I have written.
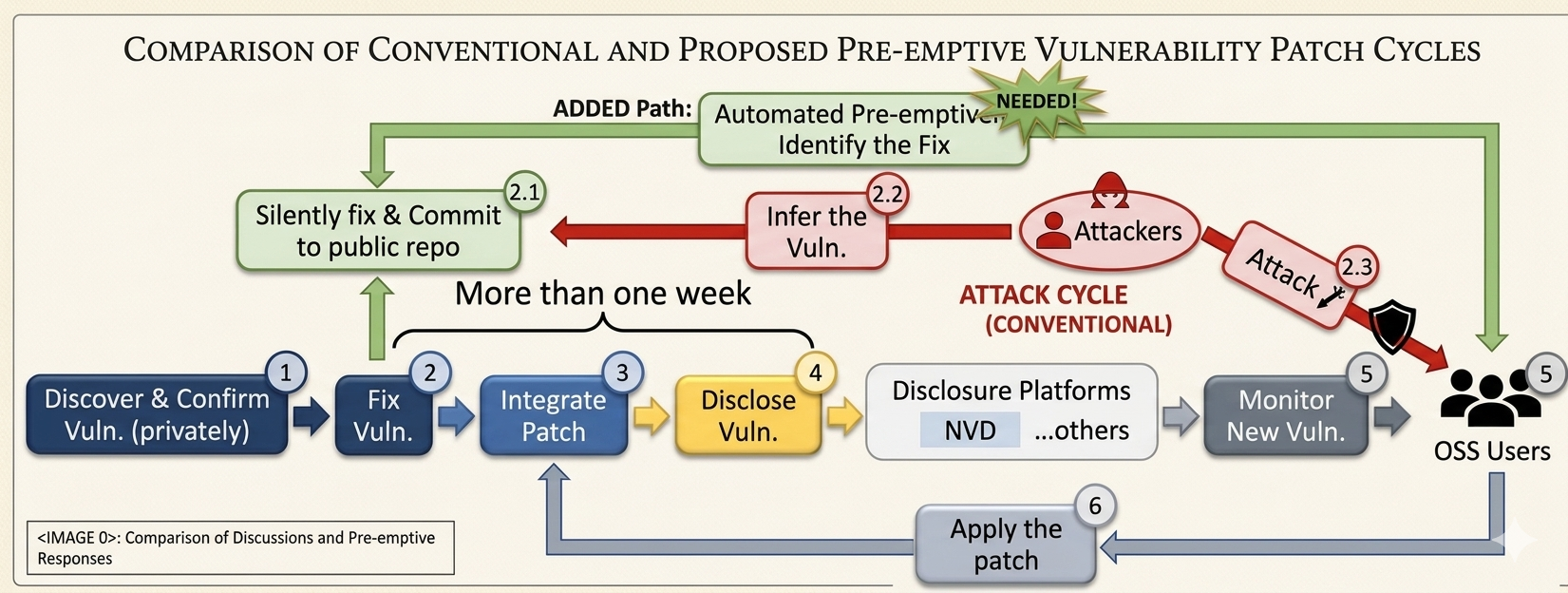
Under coordinated vulnerability disclosure, a vulnerability is typically silently fixed on the public repository weeks before its CVE is published — and attackers can infer the vulnerability from those silent commits long before defenders hear about it. In the CVE-2018-11776 Apache Struts remote-code-execution case, a silent fix sat in the public repo for about two months before public disclosure; this is the same class of exposure window that contributed to the 2017 Equifax breach (~147.9M records). Starting from our ASE'21 VulFixMiner paper, our research line has pioneered proactive vulnerability sensing — modeling silent fix commits as the first public, inevitable signal of a hidden vulnerability, covering 65% of silent fixes 1–2 weeks ahead of CVE disclosure.
OSS Vulnerability Management
Q1. How can we detect a vulnerability before it is publicly disclosed?
Q2. How do we manage that vulnerability with one hand tied behind our back — no public CVEs or advisories to draw on?
Show/Hide Work on Vulnerability Management- [OSS Disclosure Management] how OSS projects coordinate the private-to-public disclosure window
- [Industry to Academia] mapping the gap between industrial vulnerability-management practice and academic research
- [VulFixMiner] commit-only sensing, language-agnostic
- [CoLeFunDa] contrastive learning + data augmentation
- [TaintFix] taint-propagation analysis
- [MGD] multi-granularity hierarchical detector
- [LLM4VulFix] intention + dev artifacts + history
- [MoE-VulDet] mixture-of-experts detection
- [Lingering-Vul] long-unfixed vulnerability detection
- [DIR] dangerous issue-report mining
- [Auto-CVSS] LLM-based CVSS scoring
- [EAVA] evidence-augmented assessment
- [CritVul] criticality estimation
- [Diffploit] cross-version exploit migration
- [PatchPort] implicit-inconsistency-aware porting
- [SimPatch] similar-but-patched code removal
- [APR-Inject] automated repair for injections
A software-engineering agent is only as good as the procedural knowledge it can bring to bear — how this repository is structured, how its tests fail, how past developers navigated change. Our Lingxi agent framework mines that knowledge from historical development data and from its own trajectories, guiding the agent harness and feeding back into the underlying model. #1 on SWE-bench Verified (81.2%), deployed across Huawei's internal product lines.
AI Agents for Software Engineering
Q1. How do we build a software-engineering agent that handles real, repository-scale tasks?
Q2. How does such an agent keep getting better — by mining knowledge from development history and its own trajectories?
Show/Hide Work on Lingxi- [Lingxi-Miner] procedural knowledge from historical dev data
- [Lingxi-GH] #1 on SWE-bench Verified (81.2%)
- [Lingxi-v2.0] agent architecture technical report
- [Traj-Evolver] trajectories → harness + model updates
evolved knowledge feeds back into Dev Implicit Knowledge Mining — closing the data flywheel.